Whisper Pyannote Fusion
Introduction
Please note that this is a work in progress article and might be corrected, updated or amended in the future. It possibly contains errors (all mine) and to be careful when using the results presented here.
Whisper is a deep learning based automatic speech recognition system that processes an audio file and produces a json file containing information about the words and sentences spoken in the audio.
Pyannote is a set of tools and models for building speaker identification or diarization pipeline. It is able to segment the audio and identify different speakers in each segment.
If we would like to take an audio file and get the text of what was spoken but also which speaker said it, we have to use both the tools. These two tools work independently and produce separate outputs. Thus, we have to combine these two outputs or fuse these outputs.
In this article, we will go over the outputs of whisper and pyannote, the different strategies of fusing the data and the quality of the output using these techniques (at least for our data) using standard diarization metrics.
We also have all these fusion methods in a github repo and can be tested on your audio source to decide which one works best for you here at https://github.com/mochan-b/whisper_pyannote_fusion.
Why even the need for this fusion?
In first glance, this fusion should be simple. Whisper outputs segments and pyannote outputs segments. Just combine them and everything is done.
The problem is that since they are independent systems they don't produce the same segments. There might be more segments in one or the other, the segments might not line up between them, one system might think something is being spoken at one point there while the other thinks nothing is being spoken there and pyannote allows overlapping segments (since different speakers can speak over one another) while whisper does not.
In this article, we will investigate certain techniques to fuse the two outputs together and provide the code for it.
ASR and Diarization Metrics
We will compare the different methods using metrics since just looking at the results can be misleading. While metrics themselves can also be misleading, using it is an easy way to compare different methods and how well they do. I would also suggest looking at the output transcripts to double check the output looks good.
Marti/John conversation ground truth
The ground truth was a refinement of the output of pyannote output. The ground truth was human checked and labeled from the pyannote initial segments. In this audio, the pyannote segmentation is very accurate with possibly one missed sub-segment and the start and end times are also very accurate. The rationale for producing ground truth data is very labor intensive and most of this was verified using audacity labels and exports.
ASR Metrics
Given the ground truth reference text and an ASR transcriptions, the following are some of the most used metrics
- Word Error Rate (WER): This measures how many words are incorrect in the transcription. The incorrect words could be substitutions (wrong word), insertions (missing words) and deletions (extra word). So, the equation for WER is (if is the total number of words in the reference) $$
WER = \frac{S + I + D}{N}
- Sentence Error Rate (SER): Here we use sentences instead of characters or words. We can use as a binary metric where even a single character mismatch will give a zero score. Or, use some other measure of similarity between the sentences to give a score between 0 and 1, with 0 being no matches, 1 being a perfect match and something between as a number between 0 and 1. We use WER and CER to measure the similarity between sentences or many other versions of sentence similarity metrics.
Since Whisper also adds punctuation in the transcription, WER can either treat each punctuation as word or ignore them. If we use the punctuation as words, small difference in punctuation can create a higher WER score when most words are correct but there is a difference in punctuation. Thus, we can have separate non-punctuation or with-punctuation WER.
Character error rates can take longer to process since we have to compare each character and find the smallest change between the ground truth and transcript.
These metrics are calculated using the Levensthein distance which is a dynamic programming algorithm to find the minimum set of operations to change one text to the other. Because of thus, we can also backtrack and get the sequence of operations needed to change one text to the other.
Edit (Levensthein) Distance
The Levensthein distance is a measure of difference between two strings. Depending on if we have looking at characters or words, it is the number of edits (substitutions, inserts and deletions) of characters or words to turn a string to the other.
This distance is calculated using dynamic programming. The equation is given by the following dynamic programming equation
If , the distance doesn't change. Otherwise, we either do a deletion, insertion or substitution and hence, the score changes by 1.
As we mentioned above, can be characters, words or sentences to give the type of result we want.
To implement this in python, we would start with a matrix of where is the length of the reference string and is the length of the transcription (characters, words or sentences). We iterate over the and note that we will always reference a past value which we have calculated.
# Initialize the matrix
matrix = [[0 for x in range(len(hypothesis) + 1)] for y in range(len(reference) + 1)]
# Fill the first row and column
for i in range(len(reference) + 1):
matrix[i][0] = i
for j in range(len(hypothesis) + 1):
matrix[0][j] = j
# Calculate the costs using dynamic programming
for i in range(1, len(reference) + 1):
for j in range(1, len(hypothesis) + 1):
if reference[i - 1] == hypothesis[j - 1]:
substitution_cost = 0
else:
substitution_cost = 1
matrix[i][j] = min(matrix[i - 1][j] + 1, # Deletion
matrix[i][j - 1] + 1, # Insertion
matrix[i - 1][j - 1] + substitution_cost) # Substitution
To get the list of edits that we need to do, we can use back-tracing. We keep another matrix of what operation to was used for and . Then, we back-trace the sequence of operations to get the exact sequence of edits need to turn transcript to the ground truth. The method that does this can be found here. https://github.com/mochan-b/whisper_pyannote_fusion/blob/main/whisper_pyannote_fusion/wer.py#L64
Diarization Metrics
For diarization metrics, we ignore the actual text and only focus on when the different speakers were speaking. We thus have the following in the ground truth for diarization: the time intervals where speaker is speaking. If two speakers are speaking at the same time, there will be two different intervals overlapping for the same speakers.
The following are common metrics which rely on interval intersections between the ground truth and the segments and the speaker labels from the diarization system:
- Diarization Error Rate(DER): Percentage of time the segments do not match the ground truth
- False Alarm: No speaker is speaking (or perhaps music is playing) but is marked as a speech segment
- Missed Speech Rate: Percentage of speech that is missed and not attributed to any of the speakers
As mentioned that the ground truth is a refinement of the pyannote output and thus we expect the diarization metrics to measure very close to the ground truth.
Metrics for ASR and Diarization
Since we want to measure both ASR and diarization at the same time, let us examine metrics that we have for these. Both of these measures are an adaptation of the previous metrics for our purpose.
- DE-WER: Word error rate when the diarization is correct. If the diarization is wrong, the affected words are also marked error.
- WE-DER: Diarization error rate when the words are correct. If the word is transcribed wrong, it is also marked as error if the word transcription is wrong.
ASR metrics are based on text (word, character or sentence) error but diarization error is based on time. Ideally, we would have the interval for each word in the ground truth. Whisper does produce intervals for each word but that is not available in our ground truth data since is a lot of work to label each word's intervals.
Thus, we will do DE-WER-I where we will first find the best match of a diarization segment to the ground truth segment and then calculate the word error rate on it. Since our ground truth is a refinement of pyannote output as well, this seems like a reasonable measure to use here.
This method has obvious problems when a segment is broken into pieces or there are segments that do not exist in the transcript.
A better algorithm would be separate all the dialog of each speaker and do DE-WER on them. We would still need some method to match which broken segments belong to which segment and a way to remove segments not present in the transcript. There is marginal gain in our case and so leave it for future work where we do have transcripts that show a lot of such anomalies.
In our transcript, we had one case of a broken long sentence in transcript that was broken in the ground truth and 3-4 short utterances in the ground truth that were not in the transcription. We modified the ground truth and ignored the sub-second utterances for our error calculation.
Fusion Algorithms and Results
We will explore the fusion techniques and see what errors are possible to be made here.
Using Whisper segments
We will start with whisper segments and then attach a speaker to each segment. We will find the segment with the largest overlap from PyAnnote and use the label from there.
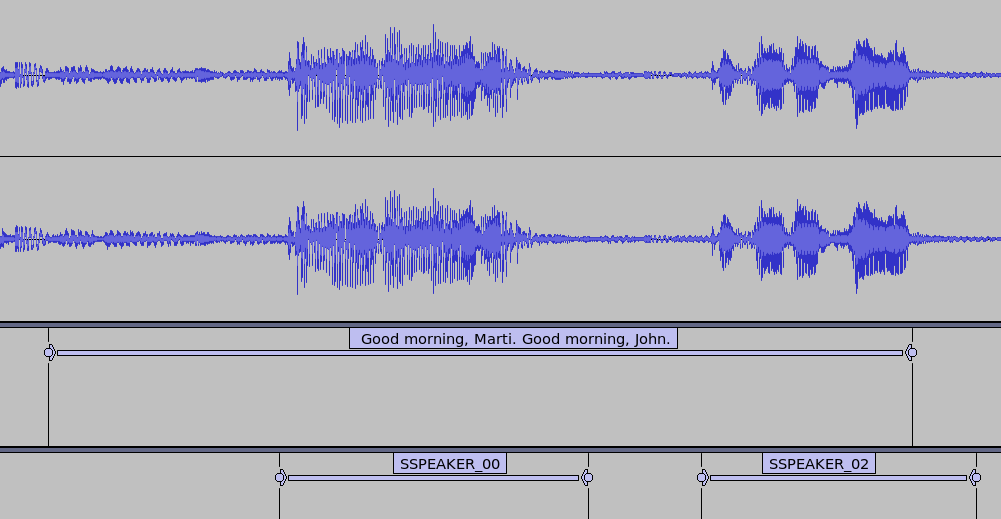
The obvious problems are like above. The text "Good morning, Marti. Good morning, John" are spoken by different speakers (ones that pyannote picks up but whisper does not).
Using PyAnnote Segments
We can start with PyAnnote segments and then use the closest whisper segment. This is similar to the previous method but with the whisper and pyannote segments switched.
This can be problematic since whisper might create a single segment for two different people talking like we described above.
Another example is that the whisper and pyannote create different intervals and whisper sometimes misses different speakers. In the image below, speaker 2 is missed and the utterance "That's right" is in the same segment as the dialog from another speaker.
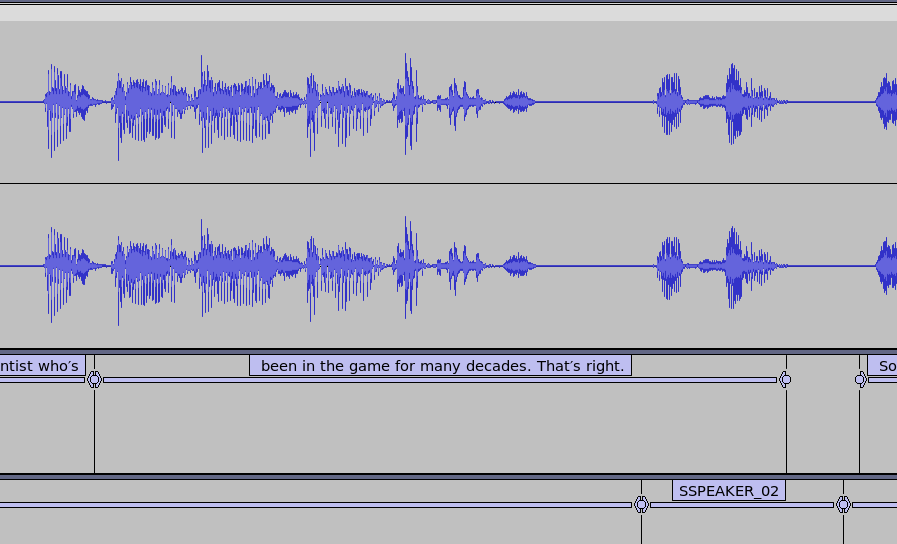
Using PyAnnote Segments to Whisper Words
Both of the above methods have their own problems.
Since whisper can output per word with the time interval for each word, we can use it to map each word to a pyannote interval or to a closest one.
Whisper does not do super accurate word time intervals and so some words are attributed to the wrong speaker.
In the following, we can see that the intervals given by whisper for words does not fall into the intervals given by pyannote (here pyannote is right and whisper intervals are incorrect).
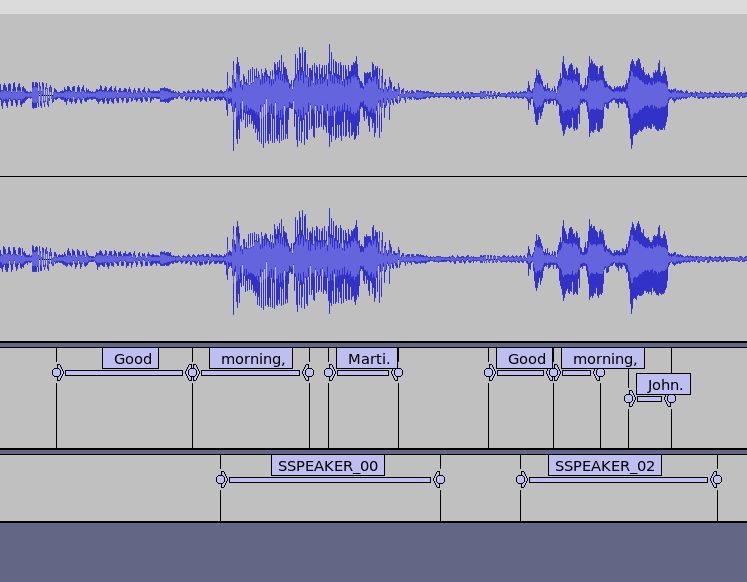
Using PyAnnote Segments to run Whisper
Another method is to first run pyannote and then run whisper on each of the segments to get accurate transcriptions. This way we might have an accurate text for each segment.
As we can see in the figure below, it did a great job with the problem we had before.
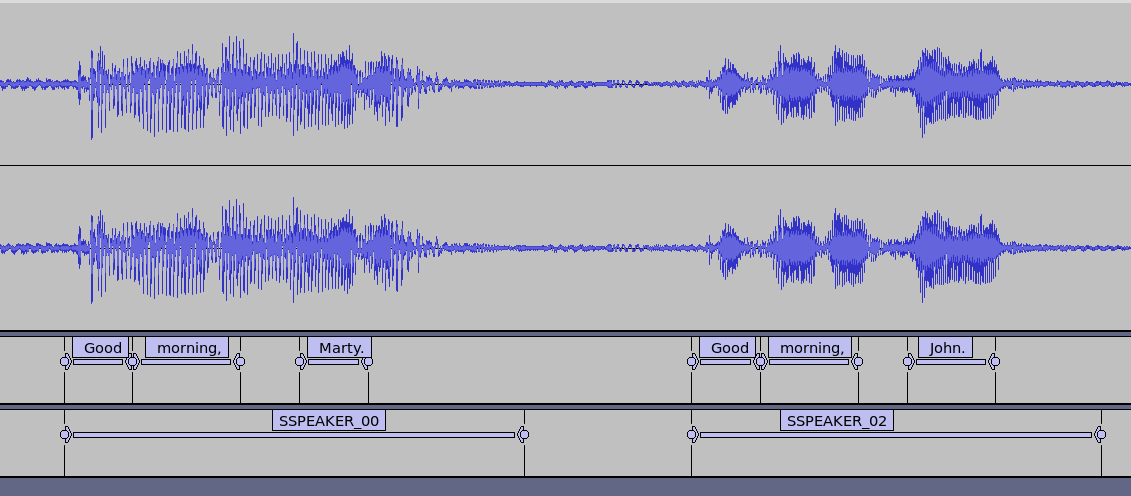
The problem is that whisper does not have the full context of the text before hand and it does lose some state information as even if we are giving it the same audio but in different segments.
Another problem is that when multiple speakers are speaking, it can pick up any of the speakers text.
If we look at the errors, we have a sample of the following errors:
marti/marty
oren/orin -and oren/orin
marti/marty chatgpt/chat +gpt as/it +is
...
chatgpt/chachi +pate levine/levin
...
dall/dali -e dall/dali -e
...
scholarphi/scholarfy
niloufar/ilifar i/ischool -school
...
yejin/agent
marti/marty
twimlai/twimmelai
Using the same Initial Prompt
Most are names and technical terms that would not be possible for the ASR to know. We do send in the initial_prompt with the speaker name and it at least gets Marti correct.
So, a smaller tune of the algorithm is to send the same initial_prompt we send to the initial whisper data, we get mode collapse and the transcription has completely unrelated to the audio or just repeats a small piece of text over and over again.
Using a summarized initial prompt
If we summarize the initial prompt to a list of the most important words, the output does improve but is still below not using any prompts.
Using PyAnnote segments to run Whisper with previous Whisper run hints
Another addition we can do is to give hints from a previous whisper run. We find all the whisper intervals that intersect with our pyannote interval and create a hint string with the text from those whisper segments. We then use spacy to remove common words and then feed in as prompt to whisper sub-runs.
However, this seems to produce worse results. It did not seem to pick up hints on names and spellings from the previous transcripts and so as a technique does not work.
marti/marty
oren/orin -and oren/orin
marti/marty chatgpt/chat +gpt as/it +is
Adding word corrections
Since adding the initial_prompt seems to be problematic with segment by segment whisper, it makes sense to go through the text and replace words that are very close with the ones from the original whisper transcript.
We use the Levinstein distance dynamic programming method but find the relevant words that can be substituted. Since the Levensthein distance method is falliable in the substitution, for example a broken word into two or an extra word can be turned into a completely different substitution.
We only substitute if the words are phonetically similar. We do this by using metaphone algorithm for similarity.
The following shows the substitutions made for our ground truth.
Marty. Marti.
Orrin Orin
Orin Orin
Oren Orin
Orin Oren
GPT-3. GPT-3…
Scholarfy, Scholarify
than then
It is successful in converting the names that were given in the prompt (Marti). However, it also makes moves mistakes from original whisper over and actually the DE-WER score decreases.
Depending on the amount of missed text, the window size of the Levensthein distance has to be increased and that will incur additional time. We are using 100 for the tests and seems to be fine but for lower values might end up not being able to successfully complete.
Using WhisperX Alignment
WhisperX has an algorithm for aligning whisper output with the sounds in the audio file using wav2vec. This does not necessitate running whisper second time but it does require running wav2vec.
This method does not always seem to succeed and does occasionally crash.
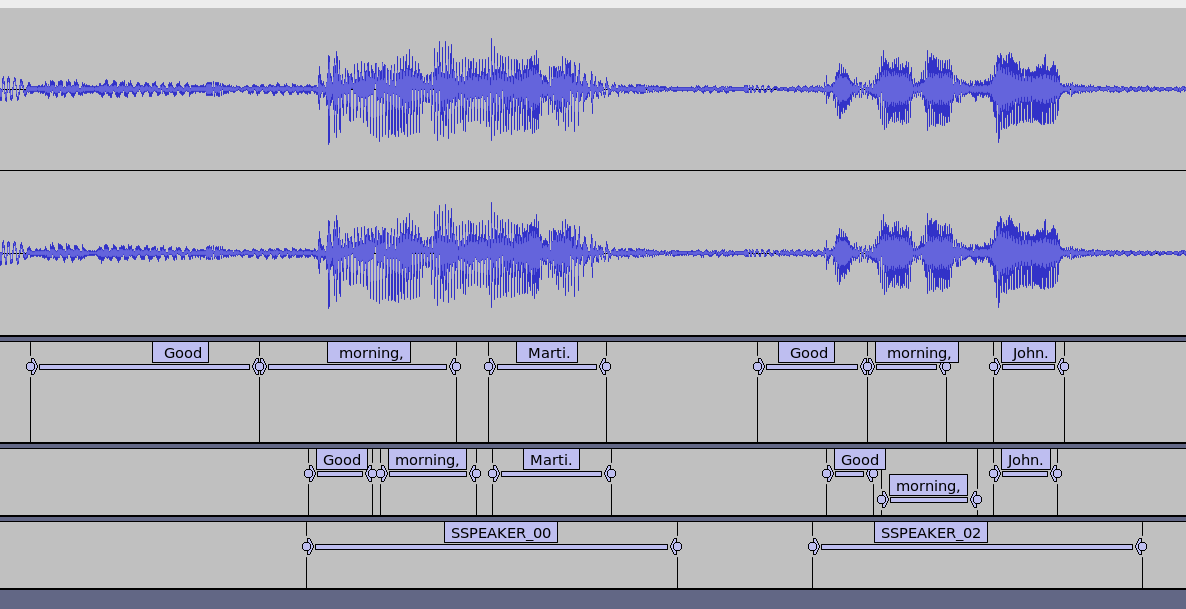
However, it does seem to align the words well as seen in the good morning segments we discussed before.
Metrics
Below are the metrics for the different methods and as we described above DE-WER is probably the best metric to compare the methods against.
| Method | WER | WER(Norm) | DER | DE-WER |
|---|---|---|---|---|
| Whisper | 0.119 | 0.084 | 0.002 | |
| Method1: Fuse Pyannote to Whisper Segments | 0.119 | 0.084 | 0.134 | 0.842 |
| Method2: Fuse Whisper to Pyannote Segments | 0.900 | 0.875 | 0.233 | 0.812 |
| Method3: Fuse Whisper Words to Pyannote Segments | 0.119 | 0.084 | 0.233 | 0.209 |
| Method4: Run Whisper on Pyannote Segments | 0.016 | 0.010 | 0.002 | 0.008 |
| Method5: Run Whisper on Pyannote Segments with Hints | 0.015 | 0.009 | 0.002 | 0.007 |
| Method6: Run Whisper on Pyannote Segments + Whisper Corrections | 0.016 | 0.010 | 0.002 | 0.008 |
| Method7: WhisperX words to Pyannote Segments | 0.119 | 0.084 | 0.002 | 0.084 |
Conclusion
The best method here is to run pyannote first and then run whisper on each of the segments of pyannote.
We do lose the ability to use an effective initial_prompt to make sure names, acronyms and institutions are spelled correctly.
If the segments are nicely split apart, then the first 3 of the algorithms would work well. Otherwise the last method of finding those words and replacing them with the correct spellings could work but also introduce extra errors.
Thus, the score for the corrections are slightly worse than the uncorrected ones. Thus, the long form whisper has better names from the hints while whisper on segments have better actual word transcribed. The difference here boils down to a few words only though.
Finally, the biggest errors are names, acronyms and other institution names. One solution is that we could have them all in the initial prompt. However, it is hard to know when errors have happened without doing manual checks.
The correct spelling for some of those names would require a web-search since it requires the complex knowledge of the personal and professional connections of the speakers, the institutions and companies that are related and technological acronyms and specific words that are not in the common lexicon. Here, LLMs would help but designing such a system that can find all of these, fix them without making errors and do so to improve the transcript is beyond the scope here but an important step to improving ASR and increasing the quality of the transcripts.